前置信息
下面是有关知识蒸馏论文的阅读笔记。其中,很多是我个人的理解与总结,若有理解或表述不当的,请斧正。
根据之前项目中的几次尝试,知识蒸馏主要适合应用于图像分类任务,对于硬性的定量指标来说有一定的提升,但是对于于图像生成和分割任务来讲,从目视效果来看,提升的不是很明显。
知识蒸馏
定义: 利用结构相对复杂的大网络(Teacher网络,以下简称T网络)来指导结构相对简单的小网络(Student网络,以下简称S网络)进行学习,以便提升S网络的学习能力。
一般来讲,T网络都是预先训练好的大模型,所以在进行知识蒸馏时,本质是如何将预训练好的大模型中的“知识”提炼蒸馏出来,以便在S网络进行训练时,对其进行监督与指导。
所以,知识蒸馏的一个重点就是对“知识”的定义,或者说,想要将T网络中的何种“知识”传授给S网络,以提升S网络的学习能力。
知识分类
从已经查阅过一些论文来看,“知识”大体可以分为三种:
- T网络最终输出Soften Label(这里主要针对分类问题而言,相当于老师直接给答案,学生由答案反推问题的求解步骤)
相比之前学生自己尝试求解,然后阅卷老师只打分,告诉其对错而不给具体答案来说,要让学生更容易学习一些
- T网络中间层输出的Feature Maps,(相当于老师给出,她/他求解过程中的一些中间结果,以提示学生该如何求解)
可能存在的问题:由于老师、学生本身的知识储备(两者本身的网络学习能力或网络架构本身不同所导致学习到的高层特征)不一样,老师的求解过程,对于学生的知识素养(受限于本身网络的表达能力),可能过于复杂,学生可能很难学习到老师的这种特定求解问题的方式或方法
- T网络学习或求解问题的流程(相当于老师给出问题求解时的大致求解流程,将老师求解问题前一步与后一步的求解过程教会给学生)
如何定义抽象出这种学习流程/步骤的知识来指导S网络?答案是很难!只能说有一些论文想要或尽可能地提炼出这种知识来供S网络学习。
另一方面来讲,即使针对上述同一类“知识”,由于Loss的定义不同(即根据老师教授的方法不同),又可以分为不同的算法;从网络整体设计上,知识蒸馏也出现了一些新的算法,主要可以类比为三种:
- 多老师教学:利用多个T网络来指导监督某特定S网络的训练;
- 带有助教的教学:T网的把知识教给助教网络TA,再通过TA教给S网络
- 自我复习式的学习:通过网络后面学习的特征来指导网络前面的训练
论文阅读
[1] 2014_NIPS_Distilling the Knowledge in a Neural Network
现在看第一篇,深度学习领域大佬 Geoffrey Hinton 的手笔。知识蒸馏的概念由来已久,但是本论文的发表重新又将一部分研究人员的注意力吸引到知识蒸馏领域。这篇论文,主要着手于图像分类问题,对应于上述所说的第一类“知识”。
在S网络进行训练时:除了原有的交叉熵损失之外,还需要加上与T网络输出的Soften Label之间的交叉熵损失。
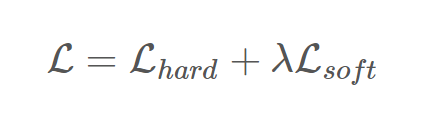
其中,在计算与T网络输出的Soften Label之间的交叉熵损失:$L_{soft}$ 时,作者对SoftMax函数做了一些小改变,如下所示,当T等于1时,就是正常的SoftMax函数:
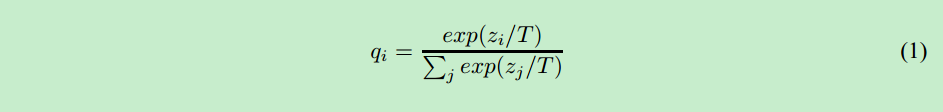

为什么使用Soften Label的交叉熵损失有助于S网络的学习,刚才用不严谨的类比说明了一下,下面从网络本身学习的角度来详细解释一下(贴至知乎问答,需要详细了解的可参考: https://www.zhihu.com/question/50519680/answer/136363665)
Knowledge Distill是一种简单地弥补分类问题监督信号不足的办法
传统的分类问题,模型的目标是将输入的特征映射到输出空间的一个点上,例如在著名的Imagenet比赛中,就是要将所有可能的输入图片映射到输出空间的1000个点上。这么做的话这1000个点中的每一个点是一个one hot编码的类别信息。这样一个label能提供的监督信息只有log(class)这么多bit。然而在KD中,我们可以使用teacher model对于每个样本输出一个连续的label分布,这样可以利用的监督信息就远比one hot的多了。
另外一个角度的理解,大家可以想象如果只有label这样的一个目标的话,那么这个模型的目标就是把训练样本中每一类的样本强制映射到同一个点上,这样其实对于训练很有帮助的类内variance和类间distance就损失掉了。然而使用teacher model的输出可以恢复出这方面的信息。具体的举例就像是paper中讲的, 猫和狗的距离比猫和桌子要近,同时如果一个动物确实长得像猫又像狗,那么它是可以给两类都提供监督。综上所述,KD的核心思想在于“打散”原来压缩到了一个点的监督信息,让student模型的输出尽量match teacher模型的输出分布。其实要达到这个目标其实不一定使用teacher model,在数据标注或者采集的时候本身保留的不确定信息也可以帮助模型的训练。
所以,作者之所以改变SoftMax函数:通过增大T,可以降低不同类别概率差异,进一步增强类内variance和类间distance的信息,以方便S网络更好的学习。
[2] 2015_ICLR_FitNets Hints for thin deep nets
算法[1], 一方面只适用于SoftMax分类问题,难以应用到其他视觉Task,并且根据上述解释,如果分类问题中类别较少时,该算法也将对S网络的提升非常有限;另一方面,只使用T网络最终输出Label来监督指导S网络训练,监督信息也偏少。
所以,论文[2]引入T网络的中间网络层输出Feature Maps信息,加入指导S网络训练。
论文[2]中,只选取了T网络中间的某一层:

中间网络层的Loss计算如下:

主要使用T网络和S网络中间隐藏层输出Feature Maps之间的L2损失,若两者的Feature Maps维度不匹配,则通过Regressor Function(一层卷积层,对应KernelSize和个数经过精心设计,以保证S网络Feature Maps经过它,维度与T网络输出Feature Maps保持一致),来解决T网络与S网络中间层Feature Maps不匹配的问题
算法[2]整体的S网络训练可以分为两个Stage:
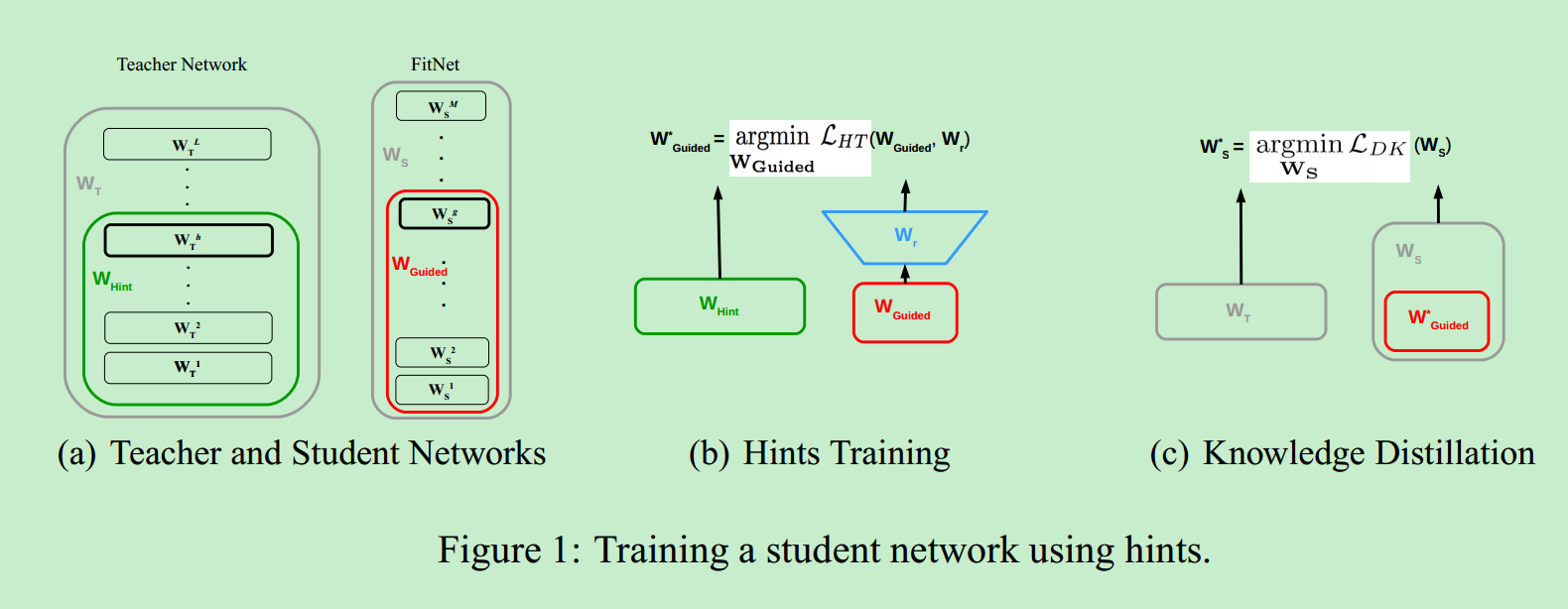
- 第一步,使用中间网络层Loss,利用T网络中截止到所选取的中间层为止的子网络,来监督训练S网络中截止到对应所选取的中间层的子网络
- 在上步预训练基础上,使用KD Loss(即论文[1]中的带有Soften Label的交叉熵损失)训练整个S网络
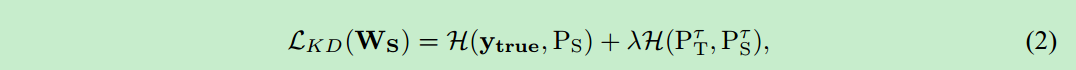
[3] 2017_ICLR_Improving the Performance of Convolutional Neural Networks via Attention Transfer
论文[3] 同样使用T网络的中间隐藏层输出,来监督训练S网络,与[2]直接使用Feature Maps相比,[3]通过从Feature Maps提取出Attention Map,用T网络的不同中间隐藏层输出得到的Attention Map来监督训练S网络的对应层次的Attention Map。
从Feature Maps提取Attention Map方法,[3]给出的三种方式:
其中A表示中间隐藏层输出的Feature Maps
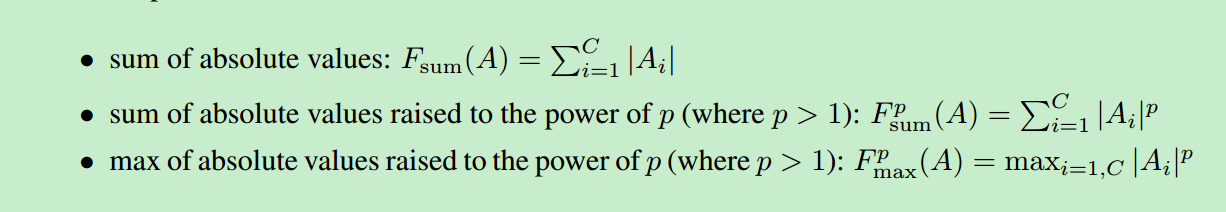
下面是在某一人脸识别网络中,使用第一种方式得到的不同Level下的Attention Maps的示意图:
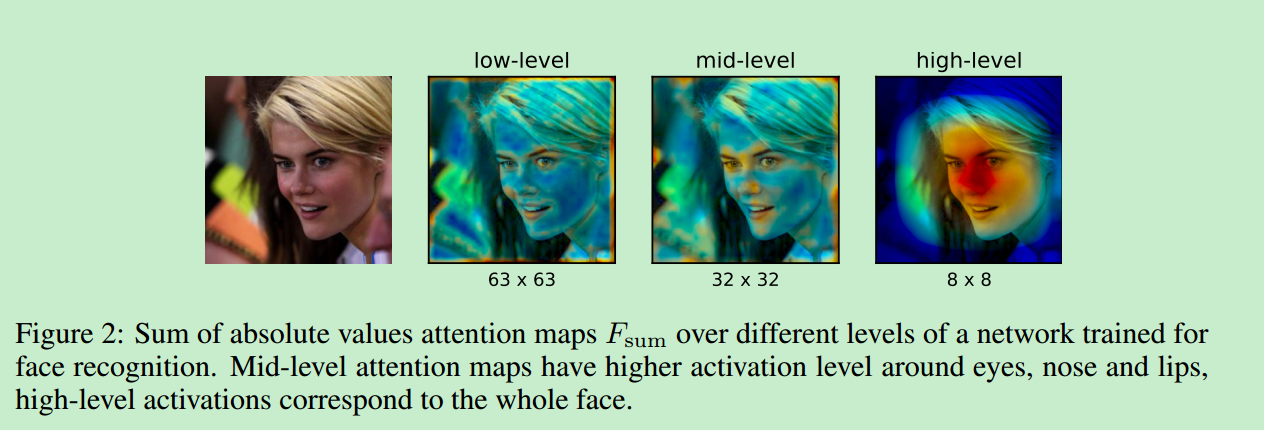
最终,[3]用T网络Attention Map来监督训练S网络的Attention Map的Loss函数计算如下:

算法[3] 整体进行知识蒸馏训练的框架如下:
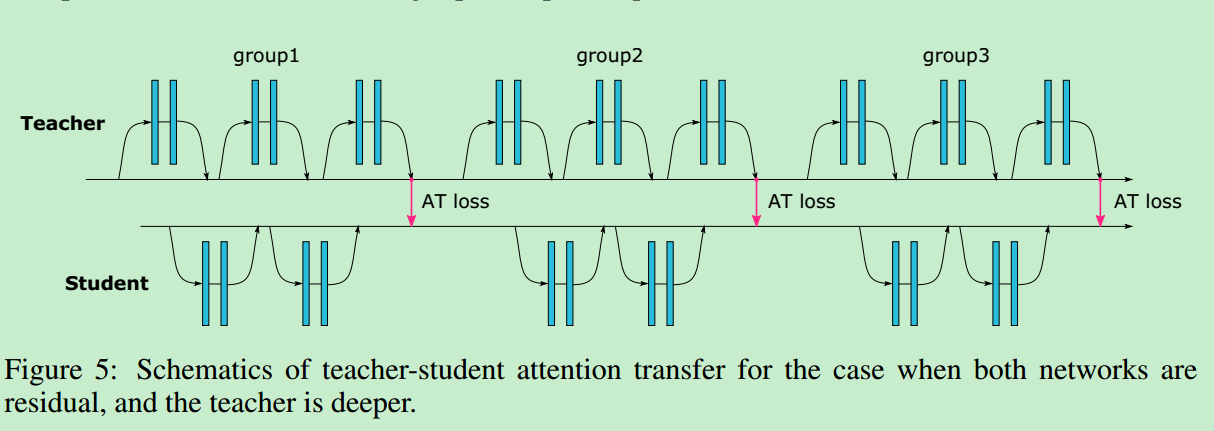
算法[3]在计算Attention Transfer Loss时,需要保证T网络和S网络的Attention Map空间尺度一样,若不一致,则将S网络的Attention Map通过缩放将其与T网络对齐。
算法[3]除了提出基于Feature Maps提取出Attention Map方法外,也提出了基于梯度计算Attention Map方法,但是效果并未有太大改善,有兴趣的可以具体参考原文。
[4] 2017_ECCV_Like What You Like Knowledge Distill via Neuron Selectivity Transfer
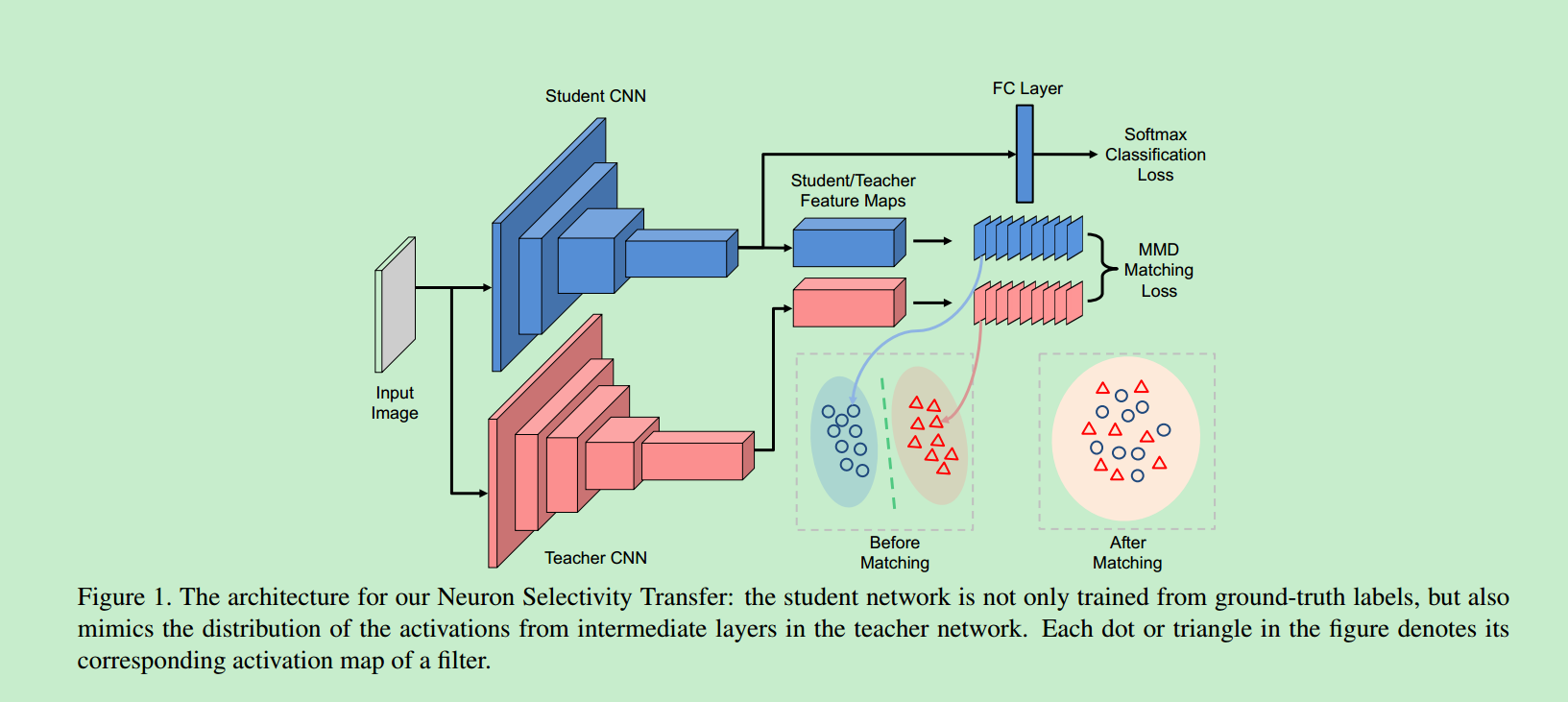
论文[4] 中T网络,同样基于网络中间层输出的Feature Maps是来对S网络进行监督训练,与[2][3]相比,[4]将T网络和S网络对应层输出的两Feature Maps看作是两个分布,利用MMD Loss加以约束,使得两分布相匹配,即S网络输出的Feature Maps对应分布与T网络相一致。

[5] 2018_ICLR_Training Shallow and Thin Networks for Acceleration via Knowledge Distillation with Conditional Adversarial Networks
论文[5] 在论文[1]的基础上,引入GAN的思想,其想要通过网络来学习一种更有效的Loss函数,而不是[1]中所设计的$L_{soft}$,如下图所示:


[6] 2019_AAAI_Multi-Model Ensemble via Adversarial Learning
论文[6] 引入了Multi-Model Ensemble和GAN,整体的网络训练架构如下:
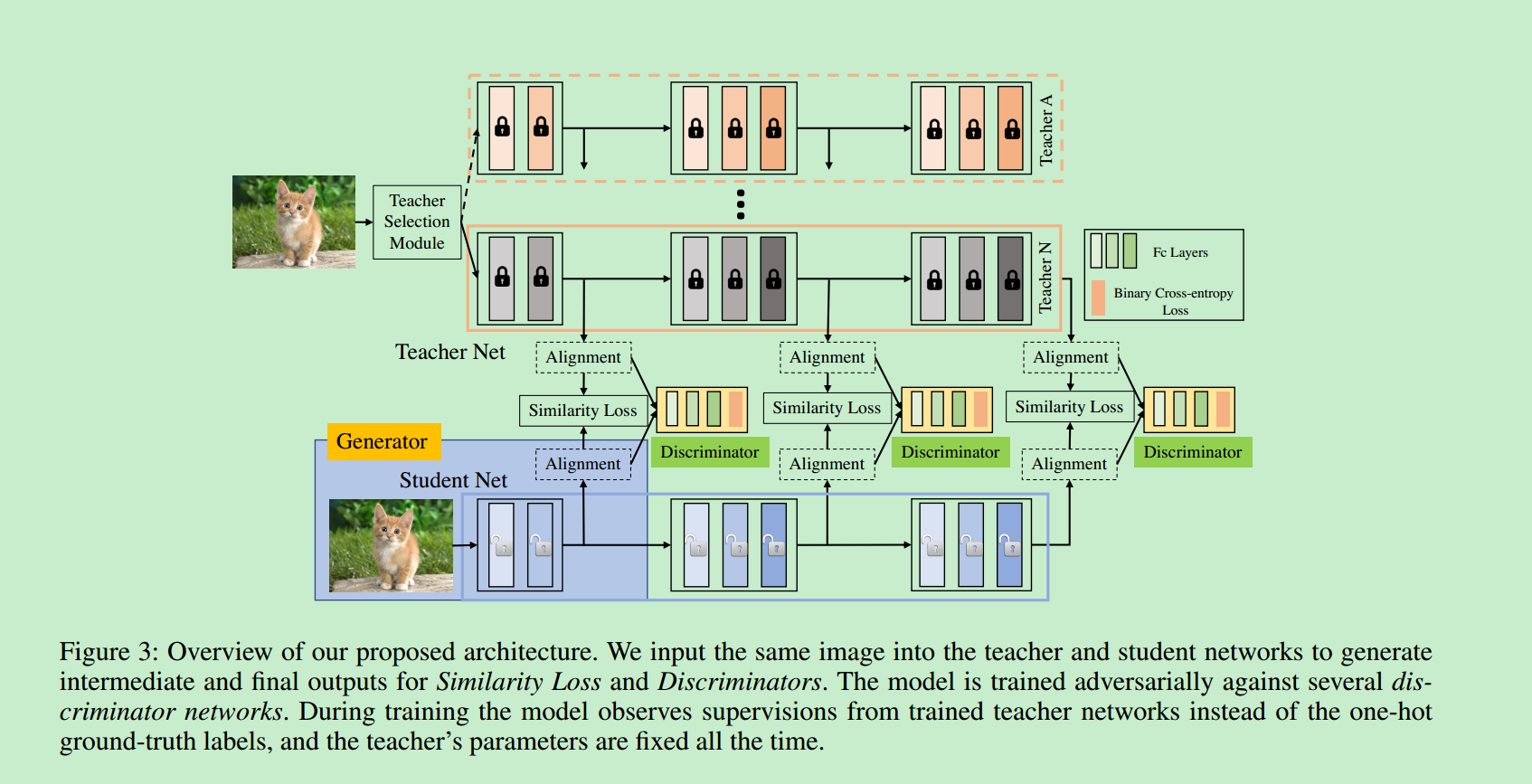
- 训练多个T网络,在训练S时,每一次迭代,随机从预训练的多个T网络中选择一个,用于指导S网络;
- 除了使用T网络最后一层的Soft Label信息以外(最后一层的Loss计算时,论文实验使用了L1/L2/Cross-Entropy,最终发现还是Cross-Entropy Loss最好),还选取了T网络中间中间输出(Feature Maps)用于指导S网络训练。为了便于求取中间层Loss,会将T/S网络的中间输出通过Adptive Pooling进行处理,使之大小一样。
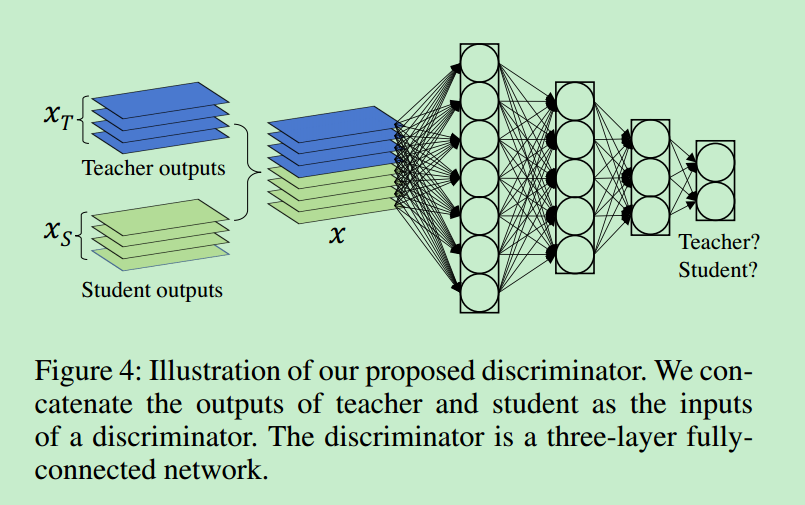
- 中间层的Loss使用了两种:Similarity Loss(论文未说明到底使用了哪种?) 和 GAN Loss
- GAN Loss求取时,判别网络输入使用了T/S网络中间层输出的Concate,主体网络使用了3层全连接层
[7] 2019_Arxiv_Improved Knowledge Distillation via Teacher Assistant:Bridging the Gap Between Student and Teacher
论文[7]实验并分析了T网络与S网络之间学习能力差异程度对于知识蒸馏的影响(具体如何实现知识蒸馏,仍然是基于论文[1])。如下图所示:
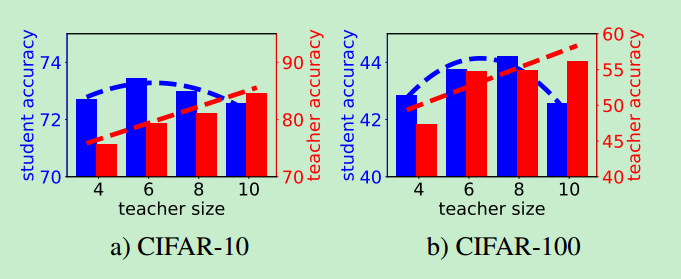
论文[7]分别针对CIFAR-10和CIFAR-100两个数据集,就图像分类问题做了一个实验:预先固定S网络的大小(比如只有两层卷积层),随着不断增大T网络的结构(图中的横坐标4/6/8/10并不代表具体的拥有的卷积层数,而是根据网络的参数量或,虚化的一个成比例的数字,用于表现网络的具体学习能力的大小),看T网络对S网络的提升分别有多少?
从图中可以分析出3个因素,一起对网络的训练造成影响:

因此,论文[7]通过上述分析,引入了一个助手网络TA(网络结构或学习能力介于T和S之间),先利用T对TA进行知识蒸馏;然后再用TA对S进行知识蒸馏。
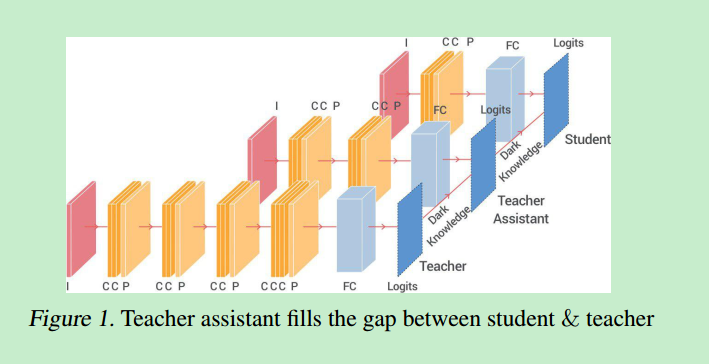
虽然TA的学习能力弱于T,导致降低了Factor 1的正面影响,但是也减轻了Factor 2、3的负面影响。最终论文[7]通过实验验证了,引入TA(不管是何大小的学习能力的TA,只要介于T与S之间),利大于弊。
[8] 2019_ICCV_Learning Lightweight Lane Detection CNNs by Self Attention Distillation
论文[8]基于论文[3],提出了自监督的知识蒸馏方法,以用于车道线检测。[8]认为,在网络训练过程中,靠前的网络层可以从靠后的网络层输出中,蒸馏出有用的知识,以监督自己的训练。
网络的整体结构如下:
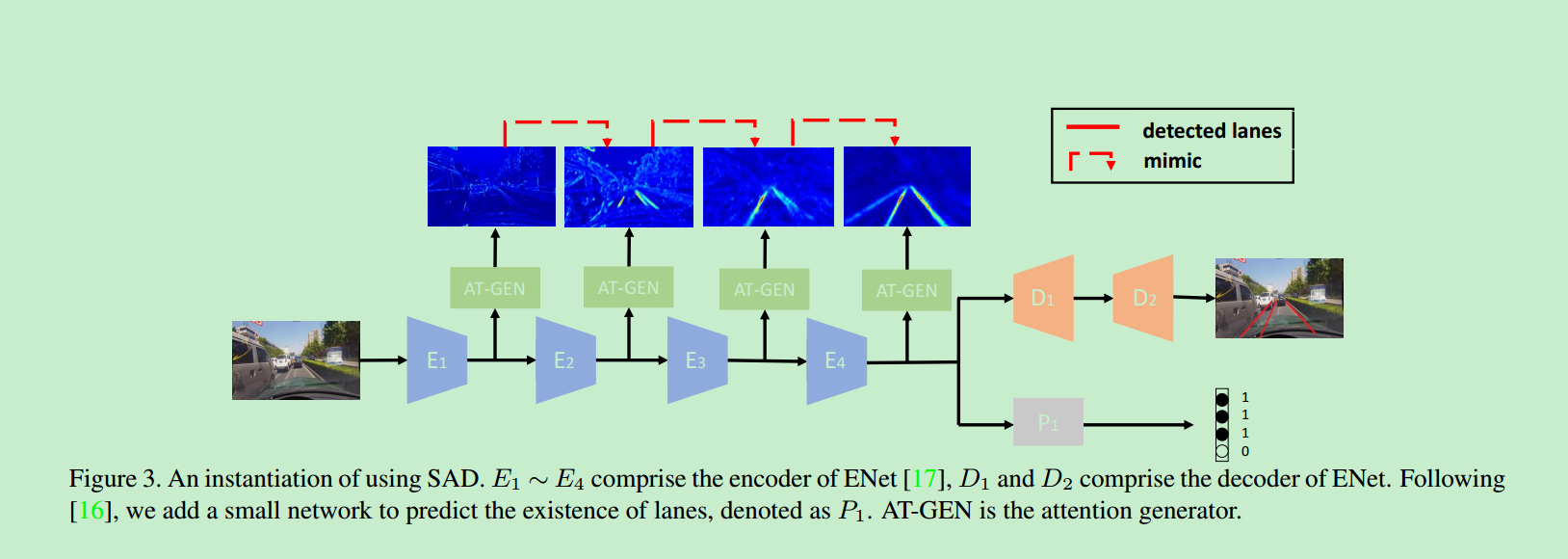
所谓的“知识”同样使用了论文[3]中的Attention Map,其计算方法与[3]一样,使用以下三种方法:
$$
G_{sum}(A_m)=\sum_{i=1}^{C_m}|A_{mi}|
$$
$$
G_{sum}^p(A_m)=\sum_{i=1}^{C_m}|A_{mi}|^p
$$
$$
G_{max}^p(A_m)=max_{i=1,C_m}|A_{mi}|^p
$$
$A_m$ 为网络的第m个网络层输出的Feature Maps,$A_{mi}$为对应Feature Maps中的第i个channel;最终论文选取使用$G_{sum}^2(A_m)$用来计算Attention Map。

其中,$\Psi(.)=\Phi(B(G_{sum}^2(.)))$,B为双线性插值函数,保证网络前后网络层输出的Feature Maps空间分辨率一致;$\Phi$为归一化函数,保证最终的Attention Map和为一。
最终,网络的总体Loss计算如下:

$L_{seg}$为标准的交叉熵损失;$L_{IoU}=1-\frac{N_p}{N_p+N_g-N_o}$,$N_p$为网络探测出车道线边缘像素点个数,$N_g$为GT中车道线边缘像素点个数,$N_o$为两者交叉区域包含像素点个数;$L_{exist}$为是否存在车道线的Binnary Cross Entropy
- 自知识蒸馏时,不一定非要使用前后相邻的两个Block输出,可以尝试进行跨Block自己的学习
- Enet的第三、四个Encoder网络结构其实基本相同,论文[8]将两者的输出Concat一起,传给Decoder以增益编码阶段所学习到的信息,提升效果。
[9] 2019_CVPR_Structured Knowledge Distillation for Semantic Segmentation
论文[9]将知识蒸馏应用于语义分割任务中,并在三种不同尺度上,从T网络中蒸馏“知识”,以指导S网络进行训练学习。
- Pixel-Wise Distillation
可以将语义分割任务看作为:针对一幅图像中每个像素点,独立进行多分类的任务。所以,可以将原有论文[1]中的知识蒸馏方法直接迁移过来,从而得到Pixel尺度的Loss函数:

- Pair-Wise Distillation
计算T/S网格输出Feature Maps之间,Spatial上对应Pair相似度,之间的差异,如下:
在这里,论文使用的是网络在输出最终分割结果前的上一层网络输出的Feature Maps(即网络倒数第二层卷积层输出Feature Maps)

- Holistic-Wise Distillation
引入GAN网络,整体上保证T/S网络输出的相似。
与之前引入GAN的论文很相似,之前由于是分类任务,所以D网络输入是T/S网络输出的Logits;现在是分割任务,输入的T/S网络输出的分割图以及原始RGB图像(由于使用了条件GAN)
最终,网络的整体结构如下:
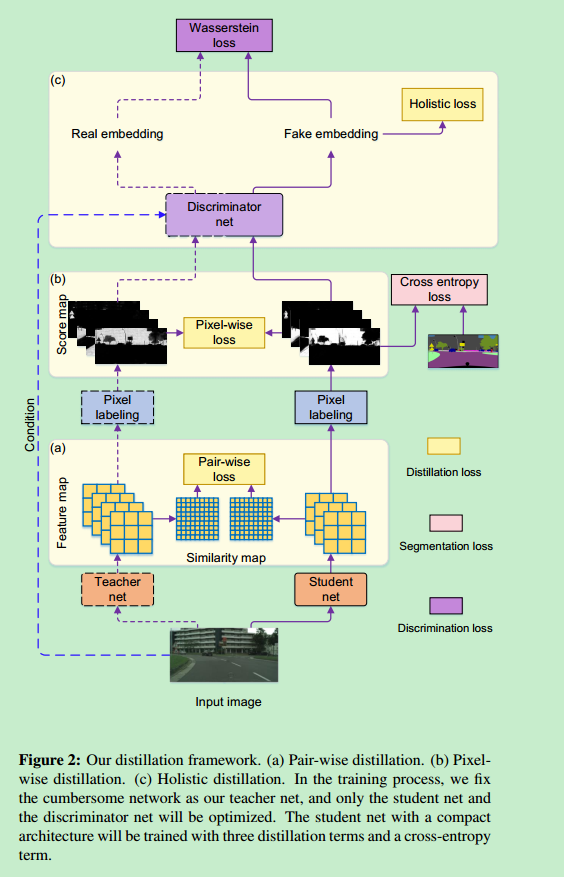
最终,论文网络训练的整体Loss是上述三种Loss,加上原有分割的多分类交叉熵损失。
[10] 2017_CVPR_A Gift from Knowledge Distillation Fast Optimization, Network Minimization and Transfer Learning
论文[10]与前面的这些论文所要提取的“知识”都不同,它首创想要将数据在T网络中的卷积层之间的“流动”,提取出来,用以监督S网络的训练。即最开始我们所提到的第三种“知识”。这种“流动”的表现,论文将之体现为不同卷积层输出Feature Maps之间的内积。
论文也提到了三点,使用上述知识蒸馏手段对S网络进行训练的优点,其实这也是大部分知识蒸馏方法共有的特点:
使用知识蒸馏进行训练的S网络,相比不使用知识蒸馏的S网络
- 收敛速度要更快;
- 效果要好;
- 能够学到一些T网络的“知识”
论文认为,如果将网络的输入看着是“问题”,网络的输出是“答案”,那么网络中那些卷积层输出可以看作是问题求解过程的中间临时结果。一个问题的求解方法是多种多样的,若像论文[2]一样,直接利用T网络中间层输出来监督控制S显然是不合时宜,这种约束太过严苛。
所以,类比人类的学习,老师在教授某一类问题的求解时,往往是想要学生学会针对某类问题该如何解答时:求解问题的求解过程。论文将这种求解过程表示为前后某两个卷积层输出Feature Maps之间的内积。具体计算如下图所示:

FSP计算是要保证前后卷积层输出的Feature Maps空间尺寸一致,若不一致,可用最大池化保证两者一致
利用T网络监督训练S网络时,就直接使用T/S网络对应FSP矩阵之间的L2损失:

最终,知识蒸馏的整体训练框架如下:
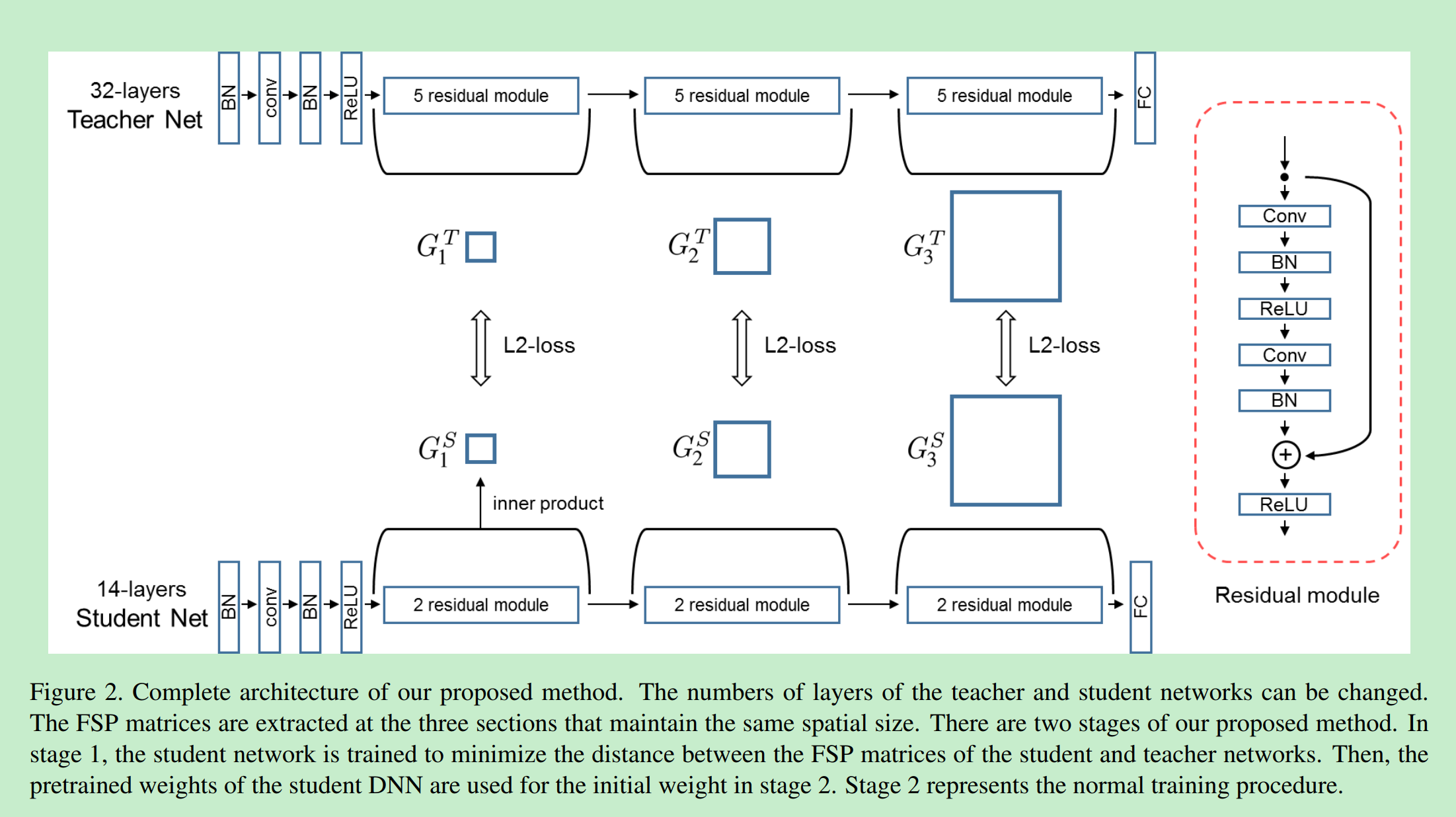
在这里论文未标明当T/S网络对应FSP矩阵维度不一致该如何处理,可能论文本身这里使用深度不一的残差网络进行知识蒸馏,在选取计算FSP时,默认考虑保证了对应FSP维度一致的问题?
整体网络的训练与论文[2]相似,分为两个阶段:
- 利用FSP损失,进行知识蒸馏,初始训练S网络;
- 在上面基础上,使用原来损失函数(根据训练,任务不同)继续训练;
[11] 2018_ECCV_Self-supervised knowledge distillation using singular value decomposition
论文[11]认为论文[10]中直接利用Feature Maps来计算相互关系时有两大缺点:
- Feature Maps一般为高维矩阵,计算复杂度较大;
- 直接使用Feature Maps形式,很难获取其中的Kownledge;
所以,论文[11]通过引入SVD,在降低Feature Maps的维度的同时,也将其转化为更容易学习的形式:即论文中的DFV。
论文整体的框架如下:
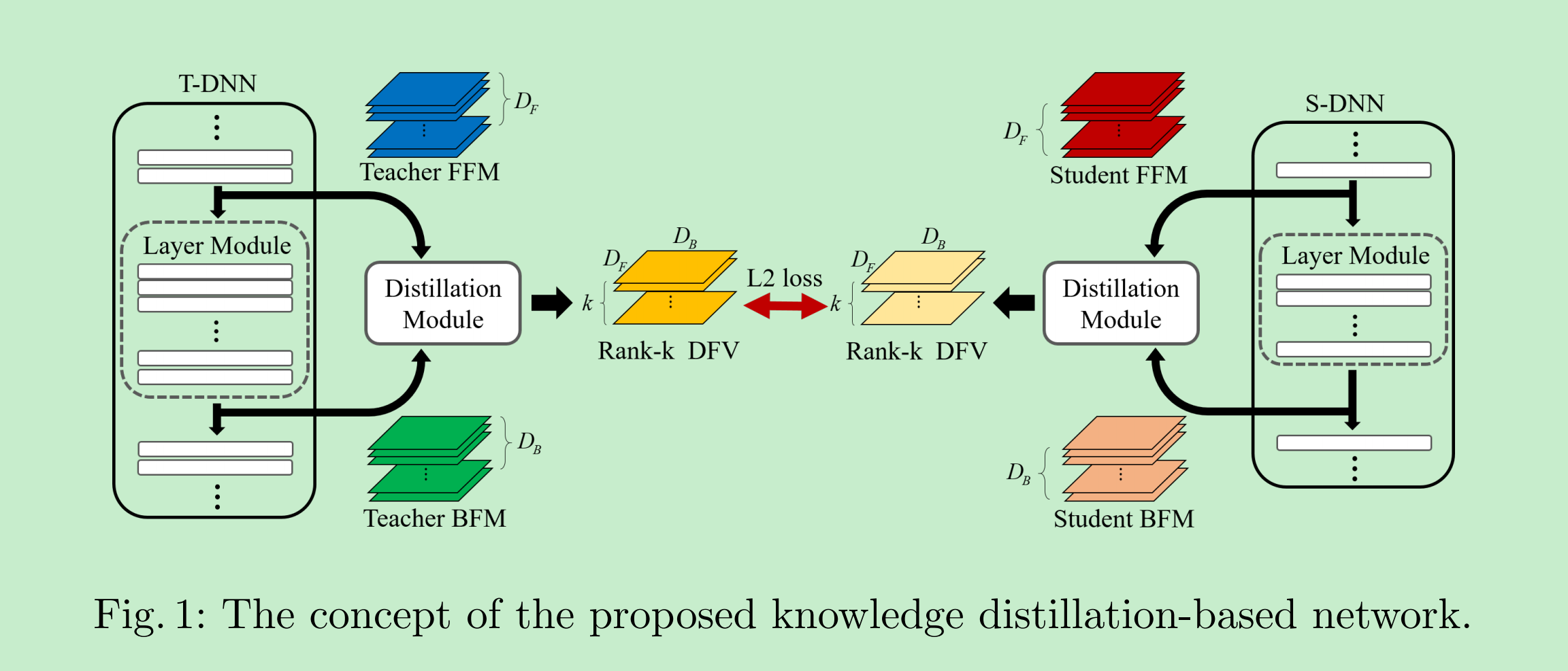
所以,论文[11]主要创新就在于如何使用图中的Distillation Module获取所要“知识”:DFV,具体如下图所示:
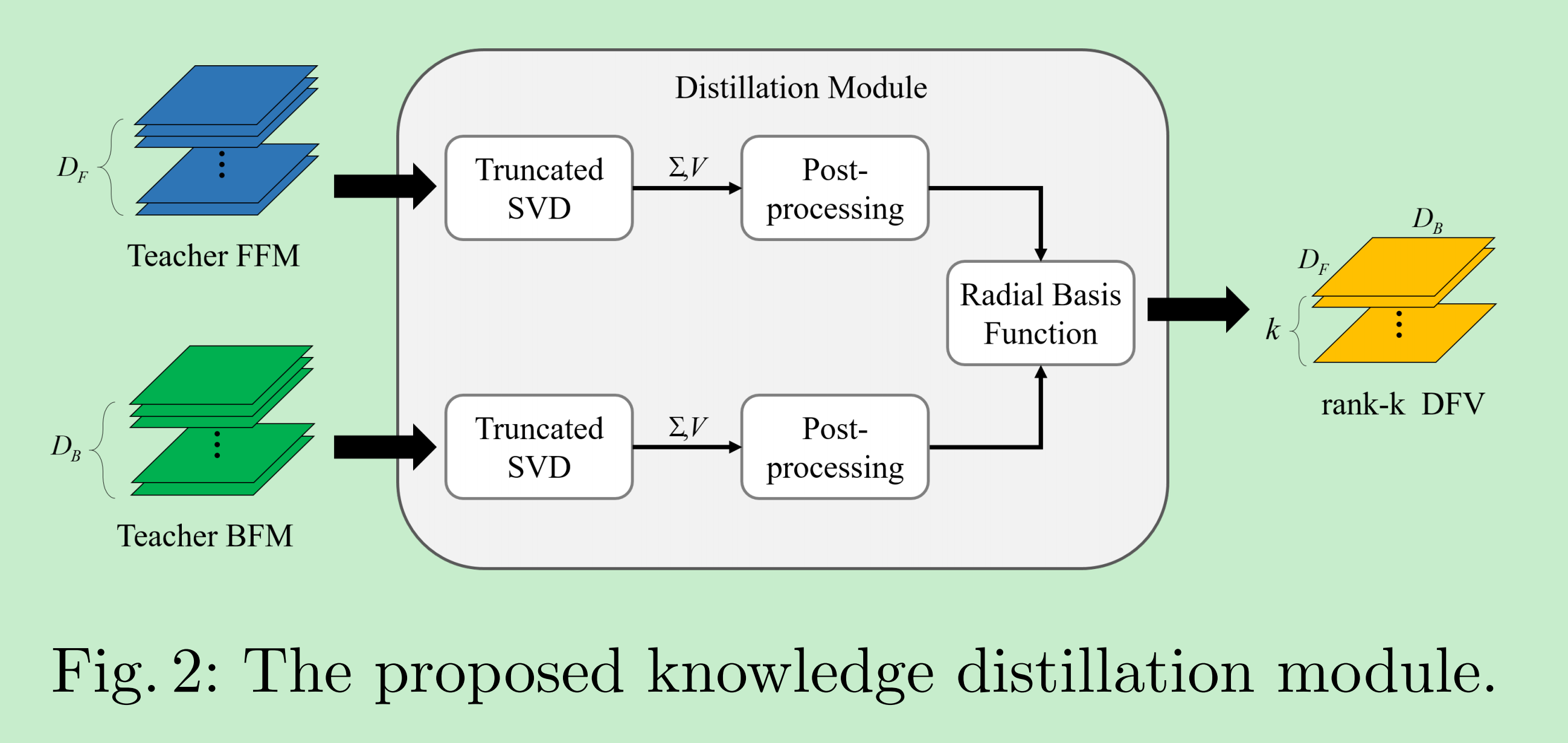

- 第一步,使用SVD将Feature Maps进行奇异值分解,并按照左奇异向量(Feature Maps中各个通道各自的特征信息),右奇异向量(Feature Maps各个通道之间的Global Information),奇异值(各个奇异向量对应的重要度)的含义,在算法中只使用了右奇异向量和奇异值。为了进一步降低计算复杂度,论文根据奇异值,只挑选的前k个奇异值与其对应的右奇异向量;
- 对上一步所得到的$\Sigma$和$V$进行归一化后处理。原因有以下两点。
- 奇异值分解时,所得到的奇异向量是按照奇异值大小进行对应排序的,因此当两个奇异向量对应Energy相似时,在T网络中的分解得到特征向量和S网络中的特征向量可能顺序会有所不同;
- 奇异向量的中元素值为$[-1, 1]$,完全相反的两个奇异向量其实信息是一致的。

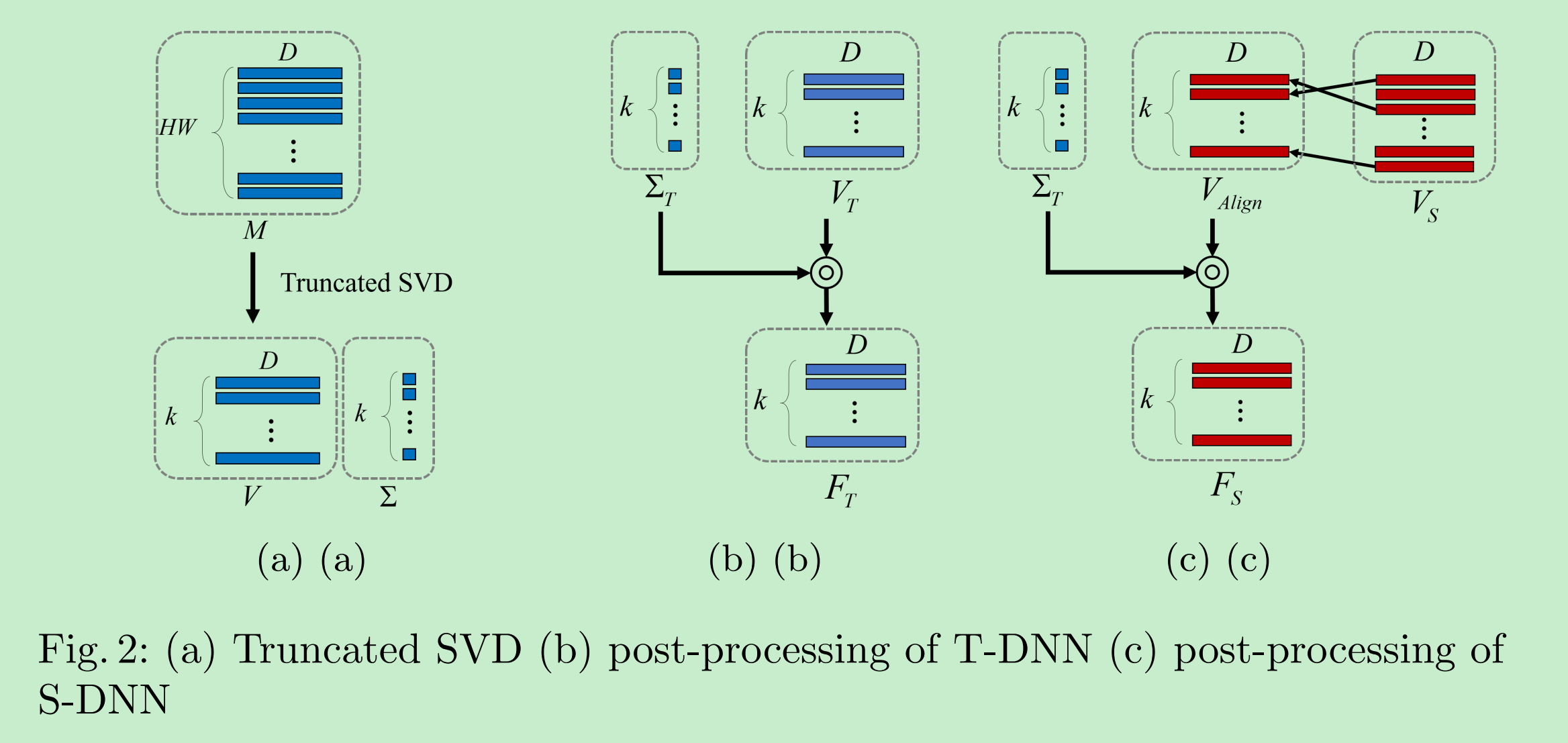
- 论文首先对T网络分解得到的右奇异向量乘上对应归一化后奇异值,以进行归一后处理;然后,利用向量之间cosine相似度(这里使用绝对值,避免完全相反的向量所计算得到的差异却认为很大),依照T网络的右奇异向量,找到其S网络中对应的右奇异向量,进而使用T网络的奇异值对其进行归一后处理:



- 最终,由于前后Feature Maps得到的归一后的右奇异向量彼此之间是相互独立的,所以,在这里计算两者之间相互关系时,使用了向量之间Point-Wist L2距离,如下所示。另一方面,为了去除SVD分解可能引入的噪声,利用RBF核加以抑制。

可以看出最终得到DFV的维度,与Feature Maps的空间尺寸无关,只与其深度(Channel个数)有关
最后,论文通过求取T网络得到的DFV与S网络中对应DFV之间的L2损失,来监督训练S网络。

其中,$G$ 为进行知识蒸馏时,所选取计算DFV的个数。
[12] 2019_BMVC_Graph-based Knowledge Distillation by Multi-head Attention Network
论文[10]使用FSP,论文[11]使用DFV来表征“数据的流动”,或前后卷积层输出Feature Maps之间的关系,或问题求解时,中间求解过程。
论文[12]则通过引入自然语言处理中经常用到的注意力机制,来求取或表征数据是如何在卷积层之间进行“流动”的。
其主要作用如下:
具体内容不在这里展开,有兴趣的可参考论文:“Effective approaches to
attention-based neural machine translation” 和 “Attention is all you need”

论文的整体框架如下:
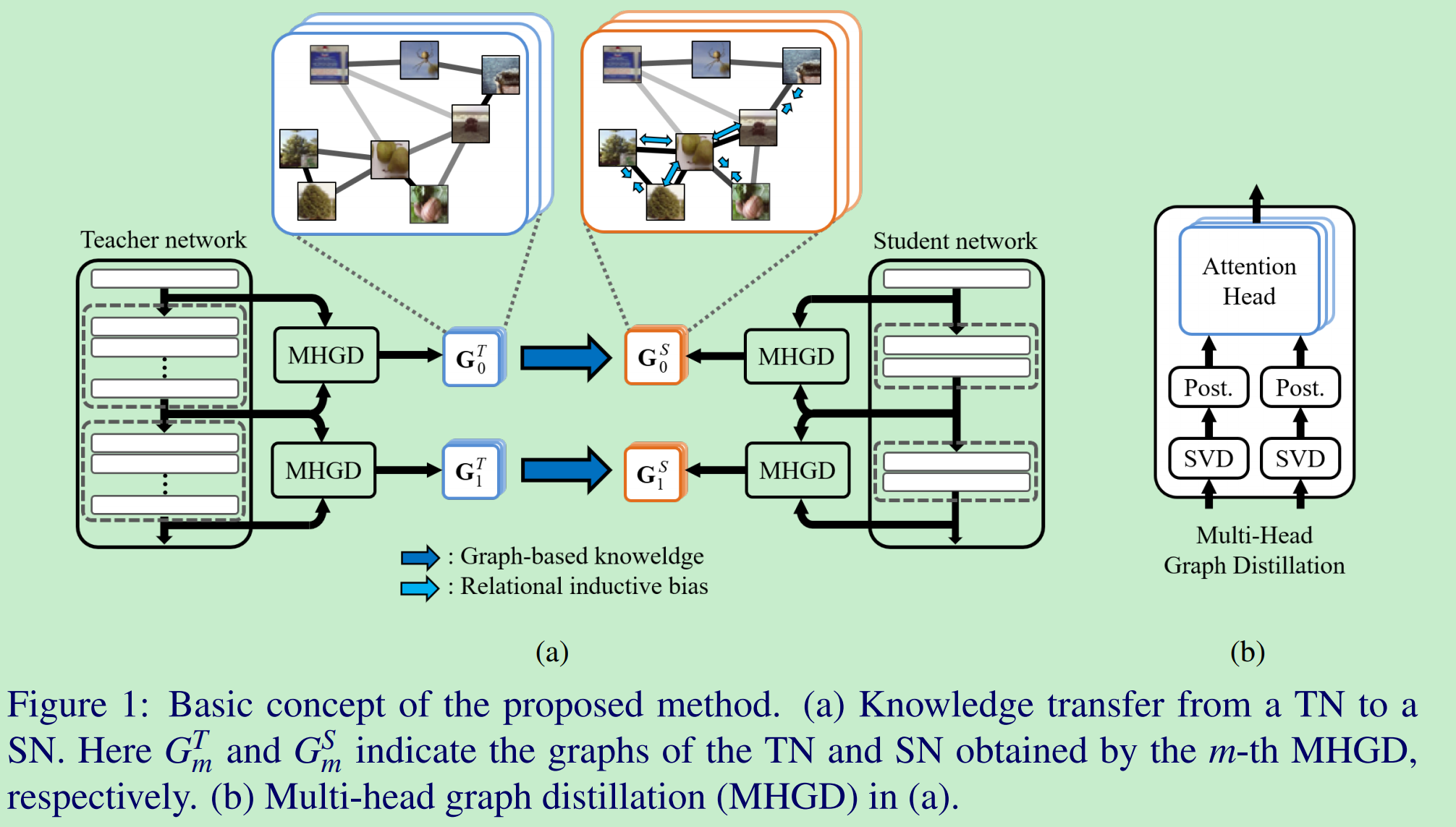
论文的整体训练可以分为两个阶段:
- 训练MHGD中的MHA,也是本论文的核心,具体网络结构如图2所示。其训练过程类似于编/解码器的训练,最终在知识蒸馏时只使用了其中的“编码器”,即MHA:用于计算两个Feature Vector Set之间的关系;
- 通过上述训练好的MHA,利用T网络对S网络进行监督训练。
MHA的输入是经过了论文[11]中KD-SVD进行前处理得到的Feature Vector Set,具体如下所示。
KD-SVD针对每张图输入,处理得到的是k个右奇异向量,论文这里默认得到的是单个向量,论文本身也没有详细说明如何得到?k个向量首位向量组合形成?

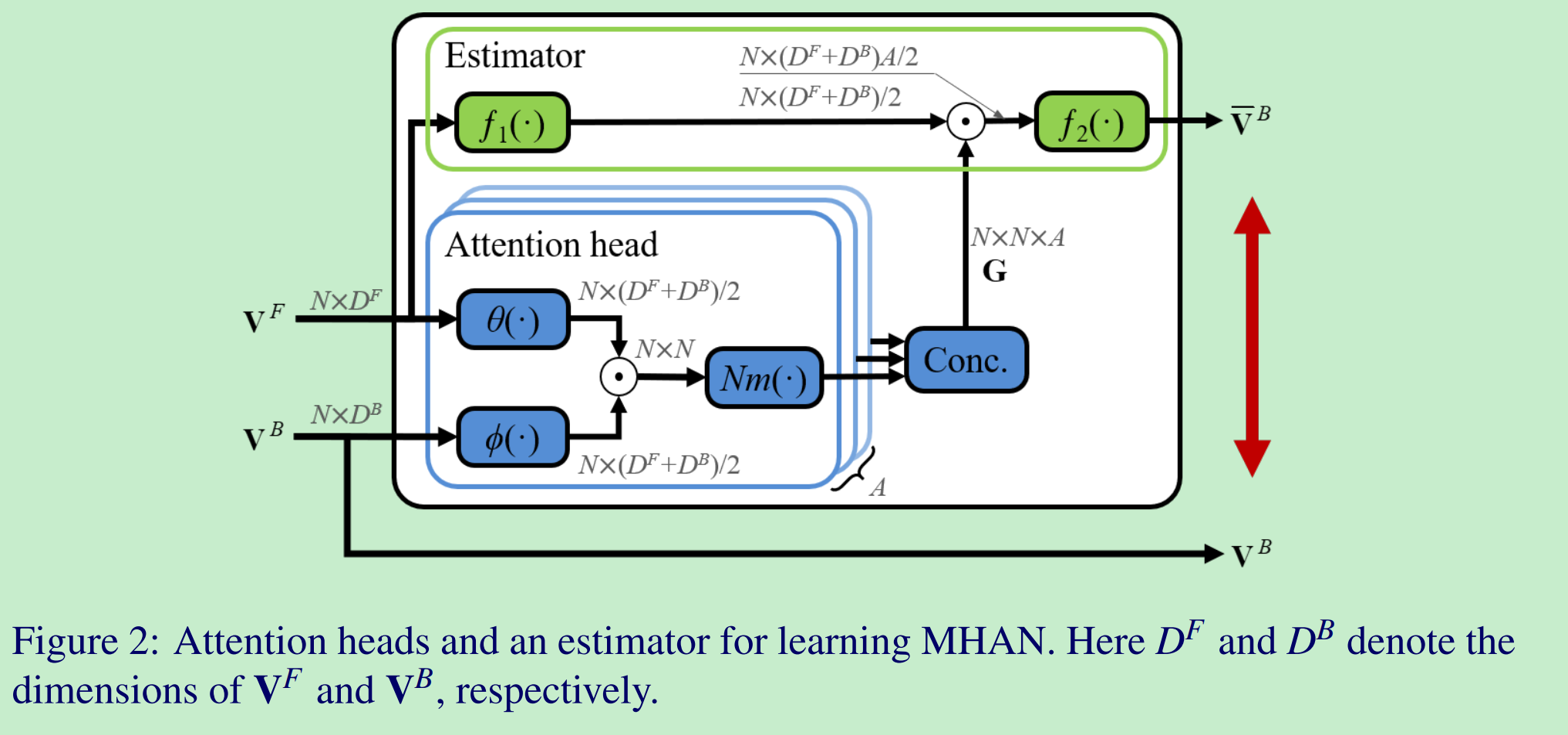
MHAN包含了多个AN,每一个AN结构如下:首先通过全连接层将前后Feature Vector Set的维度匹配一致,方便后续相似度计算;然后计算两个Feature Vector Set之间的相似度similarity map,计算方式如公式2所示;之后,对similarity map进行行方向上的softmax,保证similarity map中的每一行和为1;最终将多个AN输出的similarity map concat一起,组合成$G$.

因为,得到$G$是有网络可学习参数的,所以预先需要对这些层的参数进行学习(类比于编/解码器)。为了学习这些参数,后面再接一个estimator:尝试可以通过$G$和$V^F$,恢复得到$V^B$。
estimator的结构如下:

最终,MHA训练的损失使用了向量间的Cosine相似度,如下所示:
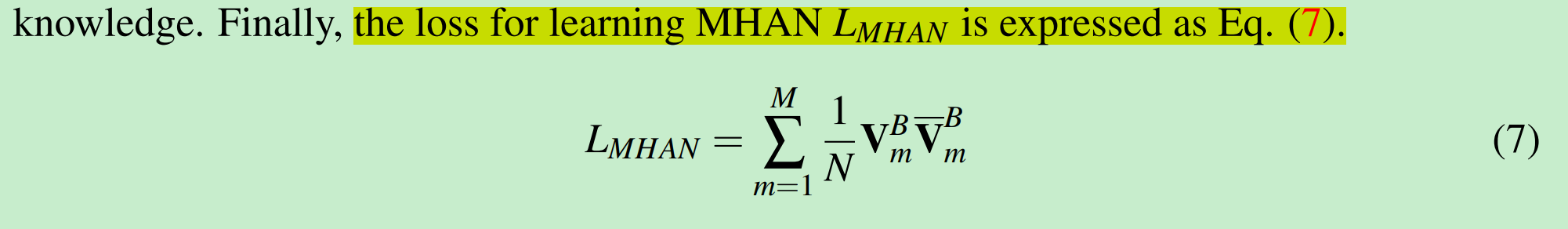
网络最终进行知识蒸馏的训练如下:
-
使用了T/S网络中对应$G$之间的KL散度损失函数用于监督训练S网络。
-
与论文[11]相似,整体训练过程分为2个Stage
